The CLARIN.SI NoSketch Engine concordancer enables detailed linguistic and prosodic searches in the
ParlaSpeech v3 corpus.
This guide provides a walkthrough of its basic and advanced functionalities, designed for linguists and
phoneticians, as well as interested non-specialists. The examples given are from the Croatian ParlaSpeech v3.
Access the concordancer for each available language:
Suppose we are interested in the Croatian verb "uspostaviti" ("to establish").
We can begin with a lemma search, which retrieves all inflected forms of that lemma thanks to the linguistic annotation of the corpus.
This query will return occurrences of various forms, such as:
A very important feature is the possibility to play each audio segment ![]() (red play button on the right side). This button plays the imminent context of the result of a query. If you want to play back the whole sentence, you can click on the metadata button at the left side of each concordance. This will give you the link to the recording of the whole sentence, but additional metadata as well, such as name, gender, age, party of the speaker etc. These metadata can be used during search as well, which will be shown below.
(red play button on the right side). This button plays the imminent context of the result of a query. If you want to play back the whole sentence, you can click on the metadata button at the left side of each concordance. This will give you the link to the recording of the whole sentence, but additional metadata as well, such as name, gender, age, party of the speaker etc. These metadata can be used during search as well, which will be shown below.
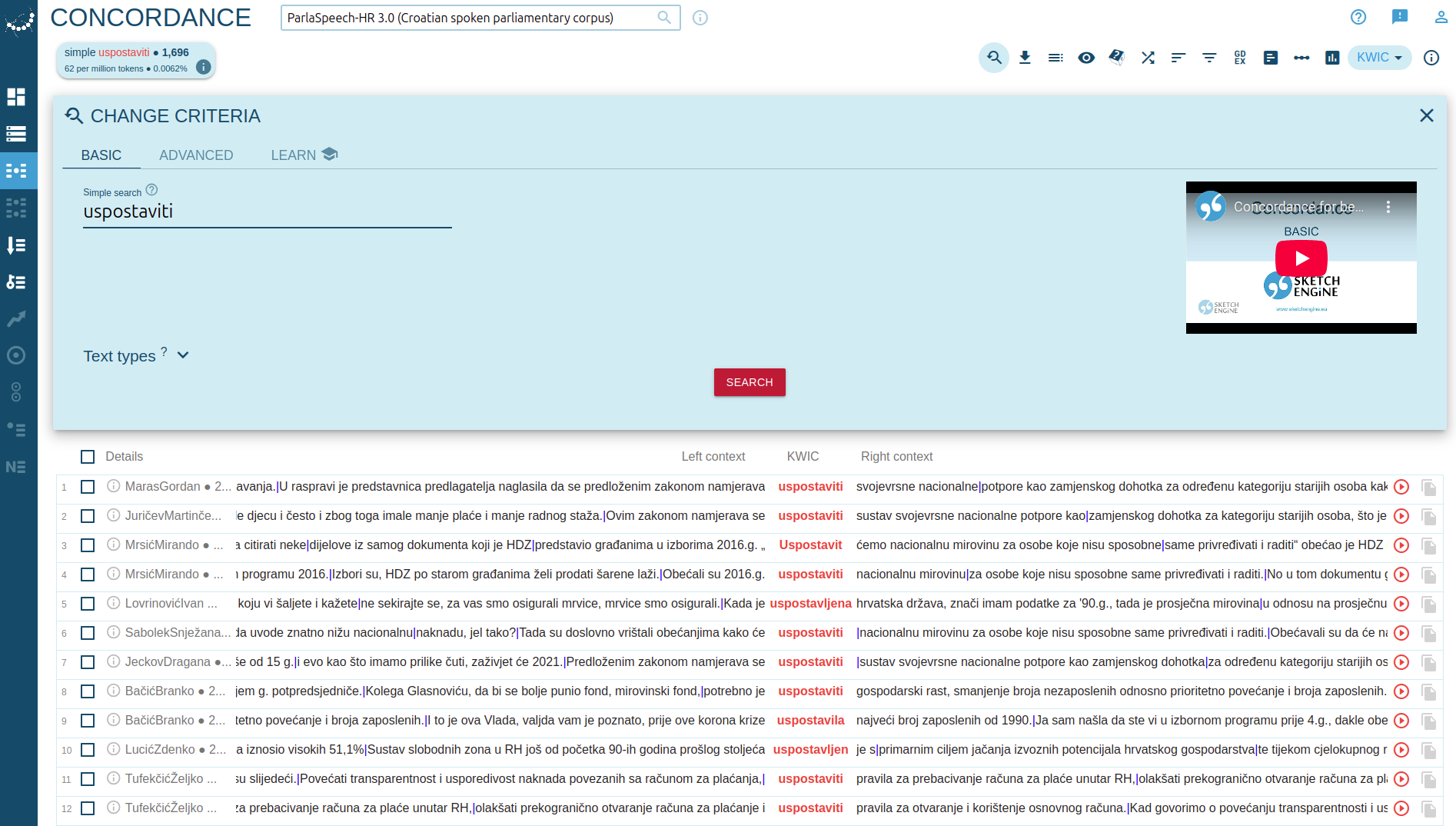
Screenshot: Simple lemma search
Let's say we are interested in a specific word form, such as "uspostavi" due to it being a primary stress doublette. We can still use the simple search and type the required word.
Why refine the search?
The form uspostavi is ambiguous. It may function as:
Given that in this example we are interested in the verb primary stress doublette, to avoid retrieving the noun use of that word, further filtering is needed via an advanced query.
To disambiguate between different parts of speech, we use Corpus Query Language (CQL) available in the Advanced tab.
In this case, to extract only the verb usages of uspostavi, the query is:
Annotation Standards:
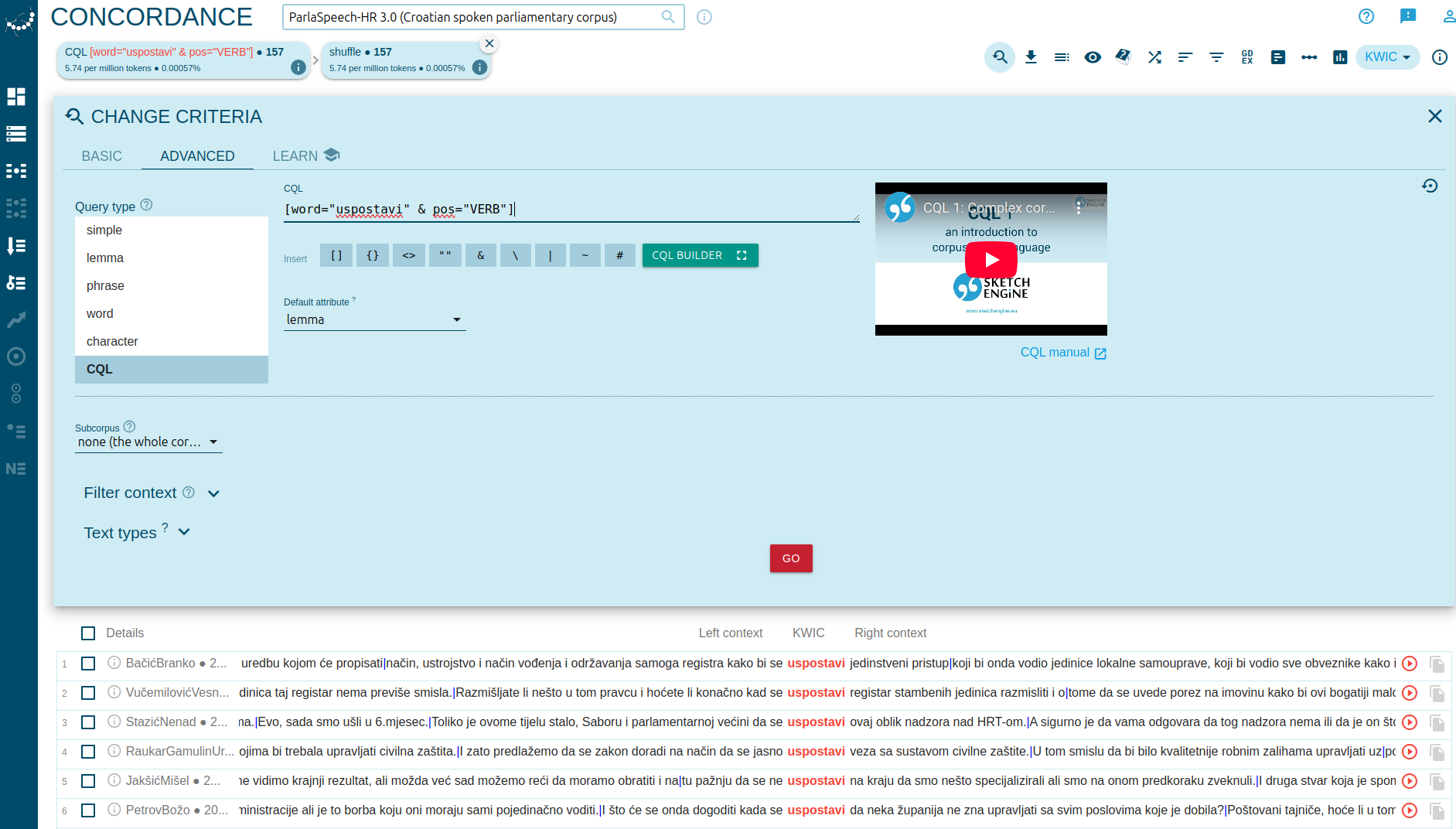
Screenshot: CQL with POS
The ParlaSpeech corpus includes prosodic annotations, such as primary stress placement.
This particular annotation layer is currently available for Croatian and Serbian.For example, the verb uspostavi is a primary stress doublette, with possible stress on the 2nd or 3rd syllable.
The query for verbs "uspostavi" with the second syllable stressed gave us 64 results. Let us investigate the same word when stress is on the 3rd syllable:
About primary_stress:
1 to N (number of syllables in the word).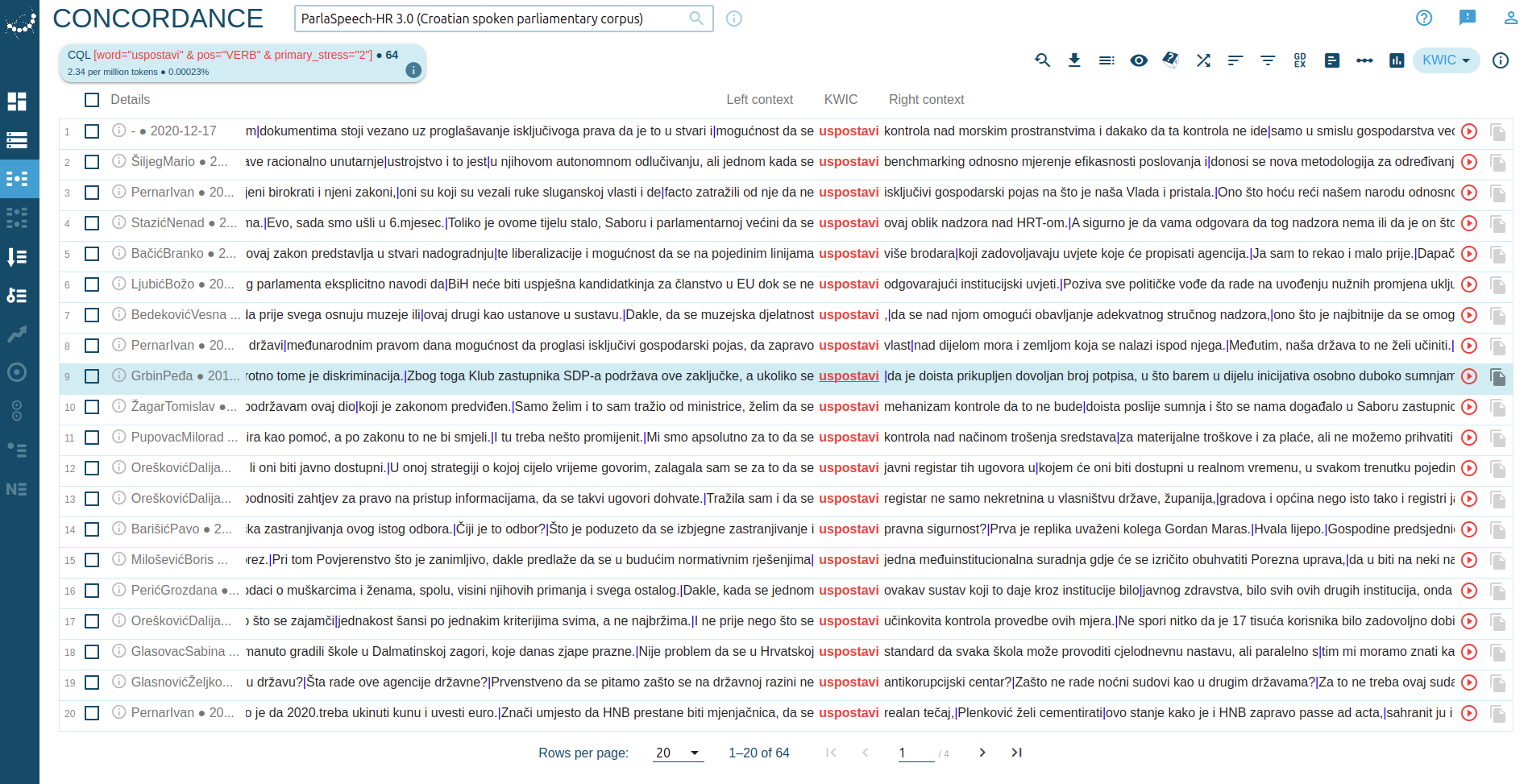
Screenshot: CQL with primary stress
The ParlaSpeech corpus also encodes disfluency markers, currently only filled pauses such as "eee" or "umm". This annotation layer is available through all current four languages (Croatian, Serbian, Czech, Polish).
To find occurrences where the word račun is followed by a filled pause:
To find occurrences where a filled pause precedes the word:
Interpretation:
fp_after and fp_before can take values:
1 – Filled pause is present0 – No filled pauseThis feature is valuable for research on speech disfluencies, planning phenomena, and prosody-syntax interfaces.
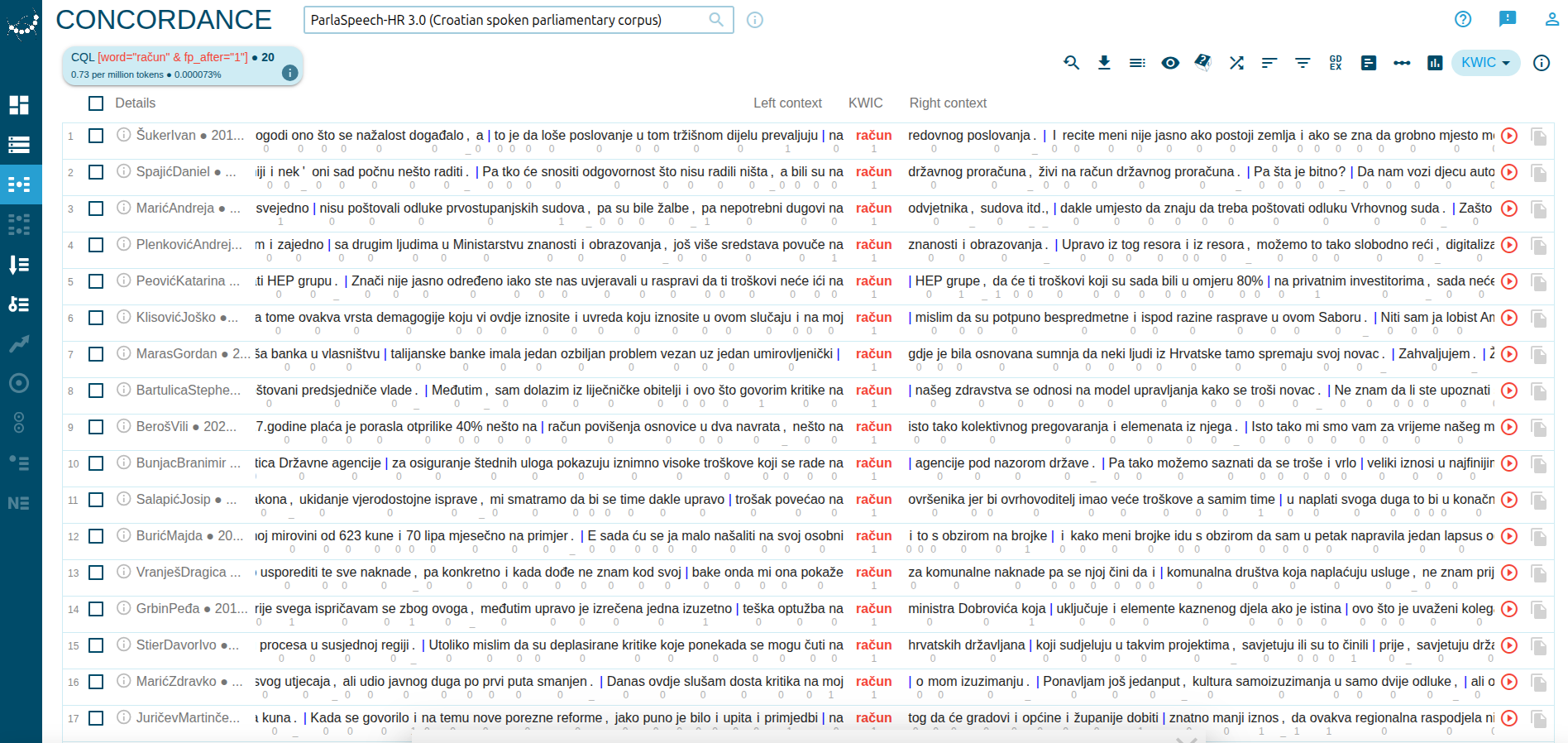
Screenshot: CQL with filled pause
The ParlaSpeech corpora encode also various metadata, such as speaker name, age, gender, party affiliation, the sentiment of the utterance predicted with the ParlaSent model.
In the Change Criteria ![]() , these various attributes can be found under Text Types. Selecting an attribute from the dropdown menu filters out the search.
, these various attributes can be found under Text Types. Selecting an attribute from the dropdown menu filters out the search.
Supposed we are interested in checking whether male or female speakers produce more filled pauses. Using the search term [fp_after="1"], we filter for all utterances with positive filled pauses events. Next, in Text Types, we select speech.speaker_gender and select M.
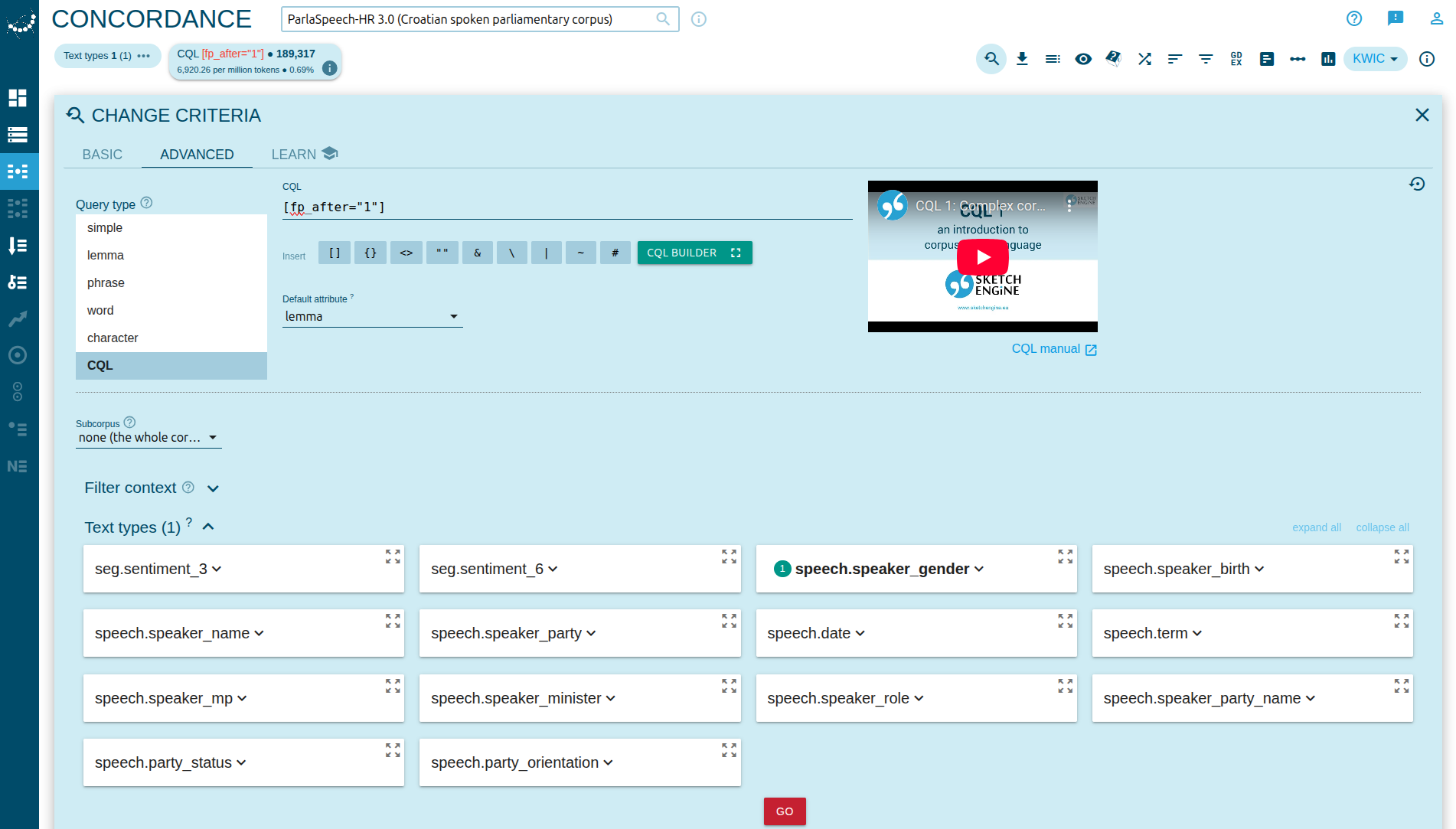
Screenshot: CQL with filled pause and Text type gender
This query returns 189,317 utteranes. By doing the same, but now filtering for F speakers, the query returns 123,344 utterances. Repeating the same steps, but now with [fp_after="0"], we find all non-filled-pause instances for both male and female speakers, resulting with the following table:
| FPs | nonFPs | Total | |
|---|---|---|---|
| Female | 123,344 | 6,301,284 | 6,424,628 |
| Male | 189,317 | 17,868,505 | 18,057,822 |
| Total | 312,661 | 24,169,789 | 24,482,450 |
Test used: Pearson’s Chi-Square Test
χ² = 28,544.00, df = 1
p = 0.00 → The difference between male and female speakers did not occur by chance.
Odds ratio (effect size, F/M) = 1.85 → Women are almost twice as likely to use filled pauses as men.
| Search Type | Example |
|---|---|
| Simple search | uspostaviti |
| Advanced lemma search | uspostavi |
| CQL: POS disambiguation | [word="uspostavi" & pos="VERB"] |
| CQL: Stress on 2nd syllable | [word="uspostavi" & pos="VERB" & primary_stress="2"] |
| CQL: Filled pause after "račun" | [word="račun" & fp_after="1"] |
| Attribute | Description |
|---|---|
| word | Surface form (orthographic) |
| lemma | Lemma (canonical form) |
| pos | Part of speech (UD standard) |
| primary_stress | Primary stress position (syllable index) |
| fp_before | Filled pause before word (0 = no, 1 = yes) |
| fp_after | Filled pause after word (0 = no, 1 = yes) |